

Debugging Drupal Redis Cache Hit Rate
I love puzzles. As a developer sometimes they end up on my lap and I get to play Sherlock Holmes a bit.
This post is to share the learnings on how I managed to track down and solve a problem that has been plaguing us for a while: a stubbornly low cache hit rate on Redis.
While there are some details that are more relevant for the stack we used, (Drupal specifically) I believe the concepts would apply in general every time you face an issue like similar to this.
Some context please
This particular issue is happening on our content API, which is essentially a Drupal 9 CMS with a GraphQL API.
Our CMS has two main use cases:
To be used as a content management platform by the editor team
To be used as a content API by our frontend applications
Given the large volume of traffic going through this system we use Redis to alleviate some of the pressure on our database.
This used to work fine and dandy but for quite some time we’ve been having a degradation on the cache hit rate and this is the bleak picture of our Redis cluster in Production 😞

Average cache hit rate in Redis
As you can see, we’re getting a pretty low cache hit rate, averaging 25% or so, not great at all.
Also, to put things into perspective our Redis cluster gets around 50k get calls per minute and processes around 2 terabytes of data! That’s a lot, so any gains here will be much appreciated.
When did this start?
First thing to do is to obviously try to identify when this whole mess started. Sometimes that’s hard to achieve, specially if it’s not something that suddenly happened, but rather a degradation that occurred slowly over time.
For us, this seemed to coincide with a very big release, when we migrated to Drupal 9.

Traffic for 3 months in Redis
Great! Easy right? Just go to the release log, check what code changed, and done! Not so much.
The first issue is that this release involved not just the Drupal platform, but all contributed modules as well, which is third party code managed by composer. It’s like trying to find a needle in a haystack.
Still, as the brave warriors we are we tried (we had some usual suspects), but unfortunately it didn’t pan out and it was becoming a huge time sink.
Time to go deeper.
Memory usage and evictions
Redis is an in memory cache, meaning it stores everything into memory (right!).
One of the first thing that got flagged to us was to check if memory was full and that was possibly a culprit.
It’s important to understand why that won’t be an issue for most cases using Redis.
The way Redis works is, it will keep caching things into memory until it gets full, at which point eviction policies will kick in, effectively removing things from the cache according to the configured eviction policy.
Obviously if the expiry time is low enough, the items might get evicted sooner and you don’t get a full memory, but that won’t help with your cache hit rate.
For us, given we use a proactive cache invalidation approach based on tags (good stuff Drupal!), we use very high expiry times like a year and then proactively invalidate them, which means triggering the eviction policy is going to happen by design.
Wait, what are we trying to solve here?
This might sound painfully obvious, but it actually took me a bit to take a step back and ask the right question
If our cache hit rate is low, what are the calls causing all the MISSes?
Basically, in a simplistic view, for every 100 calls made to Redis, 80 are a MISS, meaning they either expired or they aren’t there at all.
But how can I actually figure that out?
Redis CLI monitor
To debug any issue with Redis, Redis CLI will be your friend. It’s a very neat and easy to use CLI tool that can do a bunch of stuff from monitoring your redis traffic to giving you stats about what’s going on in your cluster.
It’s very important to note that you need to be extremely careful running monitor in a Production cluster as it will slow it down significantly.
So, the best thing to do is prepare a dev environment with the same conditions and run it there.
Once I had the env up and running, I start the monitor like so:
redis-cli -h <host-goes-here> -p 6379 monitor > dump.txt
Basically I’m telling the CLI to monitor all redis traffic and dump it into a file so I can analyse it later.
You now start seeing traffic coming through Redis.
Here is a very small sample:
1607504386.620066 [0 10.0.10.106:48690] "mget" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:x-redis-bin:container"
1607504386.620666 [0 10.0.10.106:48690] "get" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:container:_redis_last_delete_all"
1607504386.652331 [0 10.0.10.106:48690] "hgetall" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:config:system.performance"
Neat! So what do we do with this now?
The main thing we did was try to identify patterns. We knew the hit rate was very low and so most likely there was some type of traffic (the majority) constantly getting missed.
Loading the data into a tool like Splunk really helped identifying trends. The problem was, we had too much data.
Narrow things down
Remember when I told you we had 2 use cases for the CMS? The editors logging in and creating content and the API.
Only after a while did it occur to me to monitor those two use cases separately to try and narrow things down and indeed, the outcome was helpful.
CMS Editor Traffic
When I generated traffic via users logging in and using the CMS to edit content, our cache hit rate was amazing! Around 80–90% after the caches warmed up. This was very difficult to see in Production where all traffic is mashed into one.
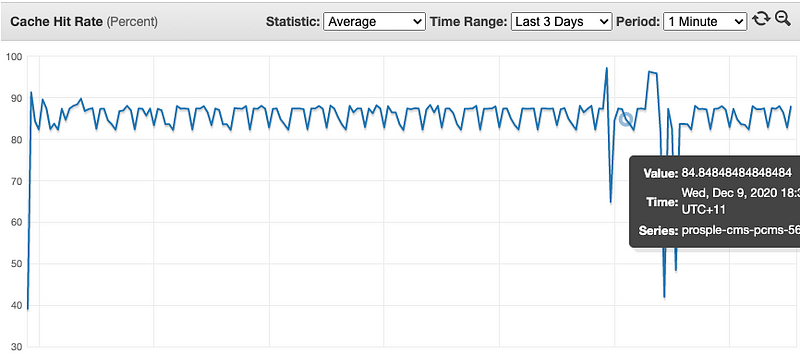
CMS Editor traffic
API Traffic
Now let’s have a look at what is happening via our GraphQL endpoint.
Once we start generating traffic via GraphQL this is what happens:
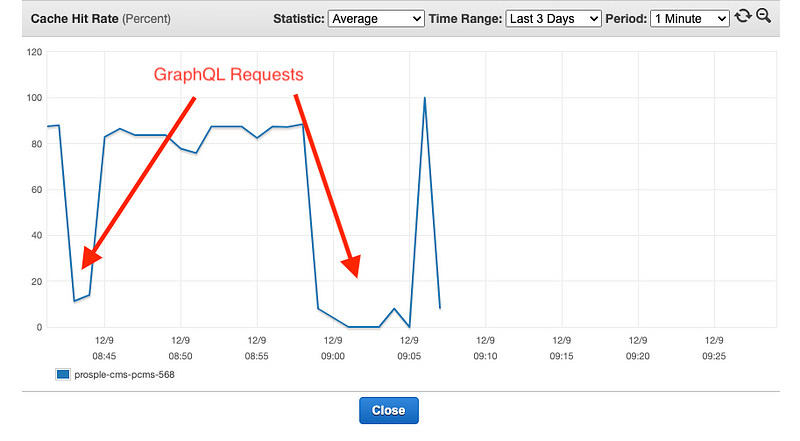
GraphQL traffic
Ouch.
Still, great news, we’ve narrowed things down a bit.
Now, to further narrow it down I basically do this with a single request. Send a GraphQL request, see hit rate dropping to 20%, let it come back up, then send a request, drop to 20% and basically confirm the pattern holds. There is definitely something happening with GraphQL requests.
Now, obviously everyone has a different use case and the above likely won’t apply, the important takeway here is:
Redis traffic is hard to monitor, so try to narrow down the issue as much as possible to reduce the amount of traffic you have to monitor
For us this meant that now I can run redis-cli monitor against just a single GraphQL request (turned off everything else so it doesn’t pollute the redis log).
Again here is a small sample of traffic for that request:
`1607504386.762256 [0 10.0.10.106:48690] "mget" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:x-redis-bin:default"
1607504386.763416 [0 10.0.10.106:48690] "get" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:default:_redis_last_delete_all"
1607504386.829198 [0 10.0.10.106:48690] "hgetall" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:graphql_definitions:fields"
1607504386.870541 [0 10.0.10.106:48690] "mget" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:config:core.base_field_override.node.article.promote" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:config:core.base_field_override.node.author.promote" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:config:core.base_field_override.node.author.title" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:config:core.base_field_override.node.campus.promote" "drupal.redis.9.0.9..ac9491ca4fcc64451a506c053106451111ecfa7173a07e39c42fecaf20db6167:cachetags:config:core.base_field_override.node.campus.title"
When I analysed the whole thing in Spunk I noticed that there were 900+ calls to redis in this request (which in itself seems too much). On top of that 600+ of those were this *.cachetags:* type of entries. That looks like a pattern worth checking.
Now, I already know that this request had a cache hit rate of 20%, which means 80% of the traffic I have (the full thing of the sample above) is a MISS.
Now I just need to figure out what it is (you can probably guess).
I took all those *.cachetags:* entries and issued gets for them in Redis and voila, 600+ nils, meaning they don’t exist in the Redis database.
Actually fixing the problem
From this point on the conversation becomes more Drupal specific, namely what the heck are those 800+ cache tags doing in my requests?
Well long story short, the GraphQL drupal module was being naughty and adding all fields we had (times the types of content we have) to our graphql schema and field definitions. This is so that if a field changes our schema (auto-generated) changes as well. The concept seems correct but there are better ways to achieve it, namely with a single cache tag.
The issue is that we use Redis as a backend to check cache tag invalidation counts and if a tag doesn’t have any invalidations it doesn’t exist in Redis. If you have 600+ tags and no invalidations, that’s 600 calls that always end up as a MISS.
So we made the change to ensure our definitions don’t rely on those cache tags and hence preventing those calls to Redis in the first place. Push the fix and run the test again.
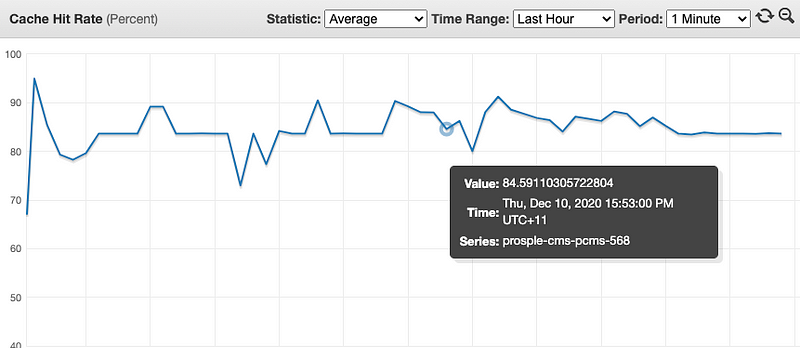
Staging traffic post fix
YES!!! It works!!!
Our cache hit rate is now averaging 90% on simulated traffic and our Redis traffic was reduced by over two thirds on GraphQL requests. Hurray!!
Wrapping up
In a nutshell, here are the things I learned from this:
Redis performance is hard to debug
Narrowing things down helps a lot
Use and abuse Redis CLI to track things down (monitor your traffic using redis cli monitor, use stats to check metrics and stats, use exists to see if tags exist on cache, and so on)
Keep cool and try one small thing at a time
Also, I’d like to send a huge shoutout to everyone in the #australia-nz community, which are always willing (and able) to help me figure these things out. You guys rock!
🙏


